It’s been a long time since my last post and I sincerely thought I wouldn’t update my blog again. I had many ideas and wanted to publish some results, or inclusive reflections about some books I had read, but then as always it happens to me, after an initial exploratory analysis, some certainly very promising and interesting, I couldn’t find the time to pursue the subject. Unfortunately the time is inevitable, at least not in relativistic terms, and then a new issue caught my attention and the former lost interest and so on; I have many inconclusive files in Python and R that will be forgotten in my hard drive, although not everything is lost, because in the way, I’ve learnt many things, new techniques, etc, and this is what is important, at least for me!!!! Moreover, then you can always recycle code for a new project, because there’s no need to reinvent the wheel every time. So, in the last months I’ve spent time fighting against so dissimilar datasets (or topics) that go from Ligo Project (Laser Interferometer Gravitational-Wave Observatory) to Dublin Bus traffic frequency, passing through raster analysis for precision agriculture .
Digressions
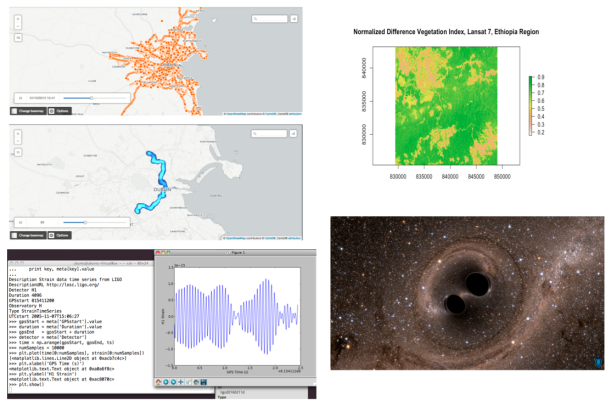
When in February of this year the press reported the detection of gravitational waves produced by the collision of two black holes, which proved an old theory of Einstein, I had the need to research the matter. I was curious to know what gravitational waves were and how scientists could prove their existence. This also reminded me when around 2012 CERN confirmed the existence of the Higgs boson, a fact without precedent, that helped to complete the standard model of particle physics. It’s interesting as a conjecture based on mathematical abstractions (e.g. it needs “something that has mass” that helps to establish equality in an equation) that can then be confirmed by means of measurements with sophisticated instruments several years later. The same happened with the theory of relativity and the total eclipse of 1919. Another day I read that the same CERN had possibly discovered a new particle but I understand that this time, there wasn’t a previous theory to prove, they found differences in the masses in a measurements and that this could be explained by the existence of a new particle. According to scientists this discovery could prove the existence of “extra space-time dimensions” or explain “the enigma of dark matter”. It’s a recent fact and it must be confirmed because it may be a measurement error, but I thought immediately, this is a curious fact, probably for scientists engaged in these topics not too much, but for a novice reader like me, I expected an “experiment confirms etc etc” and not, “we found something” and there is no previous theory that explains it. Surely with large projects being developed nowadays (LIGO, ALMA, LHC, E-ELT, etc) and many others coming in next few years, technicians will advance to theorists.
Well, in any case, I entered on Ligo Open Science Center website and discovered an extraordinary material and python codes to dive into the world of gravitational waves. Obviously, it’s necessary to be a physicist to understand everything, but for me the interesting issue was the use of the interferometry to detect variations in the signals. It’s incredible how with all instruments (in terms of calibration, I mean) they are able to isolate (filter) seismic, thermal and shot noise at high frequencies to analyse finally the “real” signal. Here the most important thing is to analyse time-series (e.g. time-frequency spectrograms analysis) applying cross-correlation and regression analysis in order to reduce RSM (SNR signals) or using Hypothesis testing (the typical mantra “to be or not to be”), signal is present vs signal is no present?, alignment signals, etc. Anyway, I did some tests and tried with some “inspiral signals”, i.e. “gravitational waves that are generated during the end of life stage of binary systems where the two objects merge into one” but I don’t have time. I love this, maybe I got the wrong profession and I should study Physics, but it’s too late. In any case, it’s interesting to use of HDF5 file format (and h5py package) that allows to store huge amounts of numerical data and easily to manipulate that data from NumPy arrays.
With regards to raster analysis, I was interested in a project that used UAVs (Unmanned Aerial Vehicles) or drones in order to analyse the health of a crop (See this news ). The basic example in this area is to work with multispectral images and calculate for example the Normalised Difference Vegetation Index (NDVI). In this case, using a TIFF image from Lansat 7 (6 channels), it’s easy to calculate NDVI using band 4 (Near Infrarred, NIR) and band 3 (Visible Red, R) and applying the formula: NDVI=(NRI-R)/(NIR+R). Simply, 0.9 corresponds to dense vegetation and 0.2 nearly bare soil. Beyond this, I wanted to learn how to develop a raster analysis using R (raster, rasterVIS and rgdal packages).
Finally, regards to Dublin Bus traffic, I only did an basic exploratory analysis of the data from Insight project available on Dublinked. In this dataset it’s possible to see different bus routes (geotagged) during 2 months. I simply cleaned data with R and then I used CartoDB to generate an interactive visualisation. It’s interesting to see for example some patterns in the routes or how they change due to some problems or how the last bus in the day does a shorter path, only to city centre, etc. Maybe I come back to this dataset, although I expect that Dublin City Council releases a new data version, current version is 2013. (See example Bus 9, 16-01-2013).
https://andrer2.cartodb.com/viz/b1fb9502-16df-11e6-8ab8-0e674067d321/public_map
GPS tracks
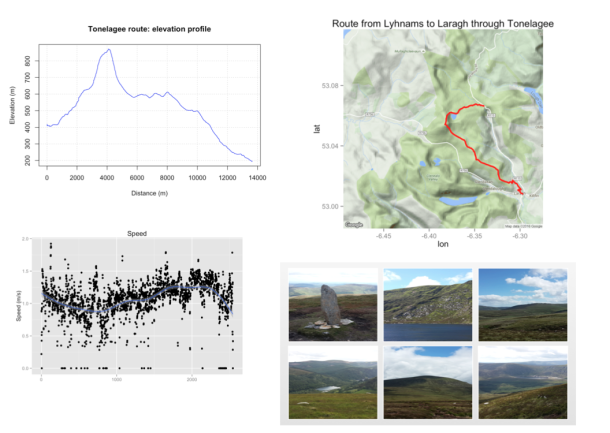
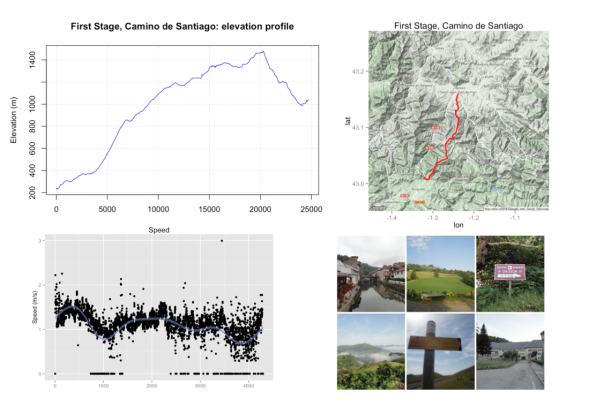
Also, I was working in others topics as for example analysing GPS tracks with R. I had two GPS tracks that gathered with my mobile phone and My tracks app during a walk around Tonelagee mountain in Co. Wicklow and another in the first stage of the Camino de Santiago, crossing Pyrenees. The R code can be found on this Rpubs
Travel Times in Dublin
Searching on Dublinked I found an interesting dataset called “Journey Times” across Dublin city. Data were released on 2015-11-19 (just one day) from Dublin City Council (DCC) TRIPS system. This system provides travel times in different points of the city based on information about road network performance. The data correspond to different datasets in csv and KML format, which can be downloaded directly from this link.
DCC’s TRIPS system defines different routes across city (around 50) and each route consists of a number of links and each link is a pair of geo referenced Traffic Control Site (sites.csv). On the other hand, “trips.csv” is updated once every minute. Data configuration is considered as a static route data and provides a context for the real time journey details. The R code can be found on this Rpubs.

Hadoop with Python: Basic Example
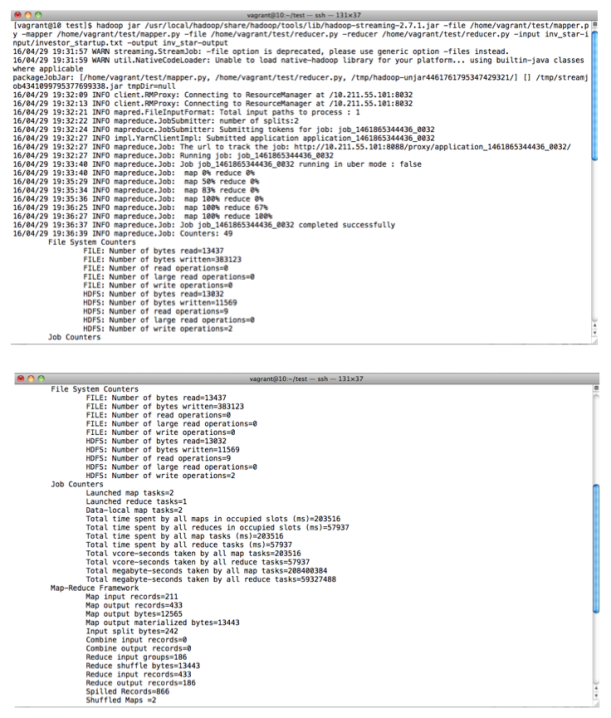
Thanks to Michael Noll website, I discovered that you can use native Python code for doing basic examples with Hadoop. Usually, the quintessential example is “Wordcount” and from there it’s possible to make small changes depending on your dataset and “voil\`{a}”: you have your toy Hadoop-Python example. I chose an old dataset used in a previous post. It’s about the relationship between Investors and companies in a startup fundraising ecosystem using data from Crunchbase (see IPython notebook).
| Investor | Startup |
|---|---|
| ns-solutions | openet |
| cross-atlantic-capital-partners | arantech, openet, automsoft |
| trevor-bowen | soundwave |
| ……. | ……. |
In this example ns-solutions invests only in openet and cross-atlantic-capital-partners invests in three startups, arantech, openet and automsoft, and so on. The idea is to apply Hadoop MapReduce algorithm to count how many investment companies invest in each startup and which they are. In each line of the dataset, the first name is the investment company and the following names are its startups. I used a Virtual Machine based on Vagrant (Centos65, Hadoop 2.7.1).
#Create a HDFS directory hdfs dfs -mkdir inv_star-input #Put dataset (txt format) into HDFS directory. hdfs dfs -put investor_startup.txt inv_star-input/investor_startup.txt #Execute Hadoop process. hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.7.1.jar -file /home/vagrant/test/mapper.py -mapper /home/vagrant/test/mapper.py -file /home/vagrant/test/reducer.py -reducer /home/vagrant/test/reducer.py -input inv_star-input/investor_startup.txt -output star-output #Show results hdfs dfs -cat inv_star-output/part*
mapper.py
#!/usr/bin/env python
import sys
#Input comes from STDIN (standard input)
for line in sys.stdin:
#Replace commas
line =line.replace(',','')
#Remove whitespace
line = line.strip()
#Split the line into names of companies
startup = line.split()
for i in range(len(startup)-1):
#Print all Startups for each Investment Company
print '%s\t%s' % (startup[i+1], startup[0])
reducer.py
#!/usr/bin/env python import sys from collections import defaultdict #Defining default dictionary d = defaultdict(list) #Input comes from STDIN (standard input) for line in sys.stdin: #Remove whitespace line = line.strip() #Split the line into Startup and Investor startup, company = line.split() #Filling defaultdict with Startups and their Investors d[startup].append(company) for i in range(len(d)): #Print all Startups, Number of Investors, Name of Investors print '%s\t%s\t%s' % (d.keys()[i],len(d[d.keys()[i]]),d[d.keys()[i]])

Books
See below the picture of my latest book purchases. Currently I’m reading “Birth of a Theorem: A Mathematical Adventure” by Cèdric Villani (Fields Medal 2010) , I have good feelings although for moments it’s a little bit indecipherable in some concepts. I must say that previously I investigated about Boltzmann equation in order to enjoy the book. Anyway, so far it’s not so clear in ideas as “A Mathematician’s Apology” by G.H Hardy (a classic,1940), although I’m willing to give it a chance.
Well, my idea, however, is only comment briefly two books. “Simplexity” by Jeffrey Kluger disappointed me because this book has not good references and bibliography and sometimes turns on obvious things. It’s true that you learn about human behaviours, but I really expected more. In fact, I bought this book exclusively for its chapter 4: Why the jobs that require the greatest skills often pay the least?, Why do the companies with the least to sell often earn the most?. In short, using or no “U complexity analysis”, it’s clear that many bosses and companies (job market in general) don’t appreciate the complexity about many jobs, It’s somewhat disappointing. Finally I recommend reading “Pricing the Future” by George G. Szpiro. For anyone who wants to learn about mathematics apply to finance is an excellent starting point. Previously to this book my knowledge about Black-Scholes equation was anecdotic and I liked how writer mixes history with mathematical concepts. The other books are excellent as “The Signal and the Noise”, already a classic in prediction, etc.